




Executive Summary
A fast-growing enterprise AI platform provider operating in the multi-agent orchestration and enterprise SaaS space set out to eliminate its dependency on a single LLM provider while preserving the integrity of its existing agent ecosystem.
The organization's platform leverages multi-agent orchestration to automate enterprise workflows, enable intelligent decision-making, and enhance user productivity. Built on the OpenAI Agents SDK, it supports dynamic agent collaboration, tool usage, and contextual reasoning.
As enterprise demand for vendor flexibility, cost efficiency, and data sovereignty grew, the platform's tight coupling with OpenAI APIs became a strategic constraint. Adopting alternative model providers was not straightforward without significant rework.
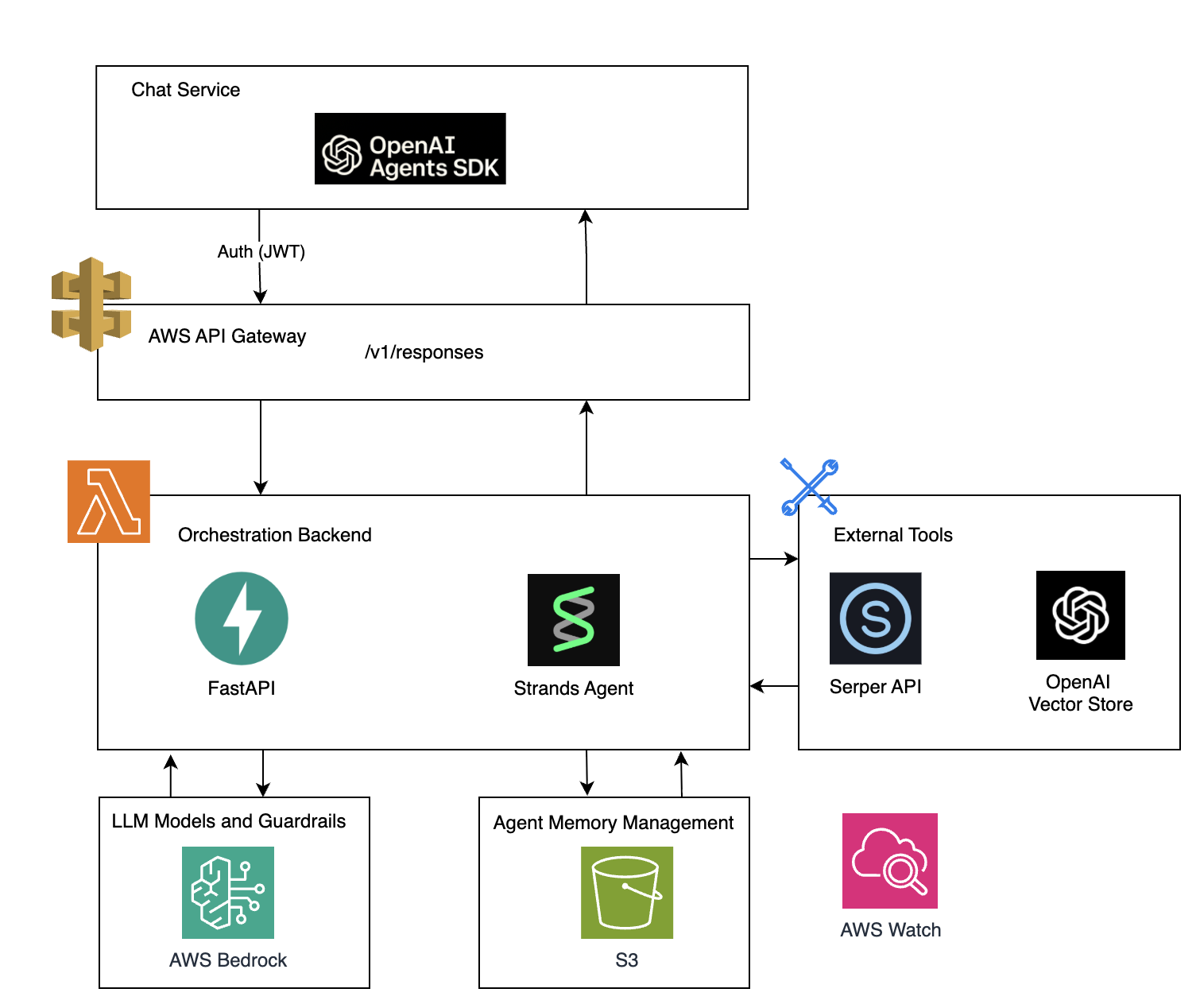
Fission Labs designed and implemented an Agents Adapter Layer to serve as a compatibility bridge between the OpenAI Agents SDK and AWS Bedrock, enabling seamless multi-provider support without requiring changes to existing agents or client-side workflows.
Business Challenge
Operating at the intersection of enterprise AI and intelligent workflow automation, the organization had built a sophisticated agent platform that was proving difficult to scale across model providers.
As the platform matured toward broader enterprise adoption, its deep integration with OpenAI APIs created critical constraints. Enterprise customers increasingly required AWS Bedrock for compliance, cost optimization, and data residency reasons. The existing architecture could not accommodate these demands without significant disruption.
Key challenges included:
- The platform was tightly integrated with OpenAI APIs, making it difficult to extend to alternative providers
- Enterprises required vendor flexibility, particularly to adopt AWS Bedrock for compliance and cost benefits
- Existing agents relied on the OpenAI Responses API format, built-in tool calling, and agent memory and orchestration logic
- Rewriting or migrating the entire system risked disrupting production workflows, required significant engineering effort, and could break existing agent behaviors
Technical Solution
Fission Labs designed and implemented an Agents Adapter Layer, a compatibility bridge that allows the OpenAI Agents SDK to communicate seamlessly with AWS Bedrock while keeping all existing agent logic and client integrations intact.
OpenAI Responses API Compatibility Layer
The adapter fully replicates the OpenAI /v1/responses API, ensuring existing agents continue to function without any modification.
- Supports both streaming and non-streaming responses
- Maintains the exact response schema expected by the OpenAI Agents SDK
- Allows plug-and-play integration with no changes required on the client side
FastAPI-Based Adapter Architecture
The adapter is built on FastAPI and serves as the central orchestration point for all agent interactions.
- Acts as the API gateway for incoming agent requests
- Manages agent lifecycle, tool routing, and response formatting
- Provides an abstraction layer that decouples agent logic from the underlying model provider
Agent Execution Using the Strands SDK
Inside the adapter, agents are executed using the Strands Agents SDK, which provides native support for AWS Bedrock models.
- Supports multi-turn conversation handling and agent orchestration
- Integrates tools natively within the Bedrock execution environment
- Allows agents to run on Bedrock models without any changes to client-side logic
AWS Bedrock Integration
The solution integrates AWS Bedrock as the core LLM provider, delivering enterprise-grade reliability alongside model flexibility.
- Supports multiple foundation models available through Bedrock
- Enables flexible model selection based on task requirements and cost considerations
- Provides enterprise-grade scalability and security
Conversation Memory Management
Conversation memory is managed through the Strands memory manager and persisted in Amazon S3, ensuring continuity across sessions.
- Persistent session storage across multi-turn conversations
- Scalable and cost-efficient storage backed by Amazon S3
Tool Calling Architecture
The system implements a hybrid tool execution strategy that mirrors OpenAI's tool-calling behavior while supporting external execution flows.
- The LLM determines whether a tool invocation is required
- Tools available within the adapter are executed directly; tools on the client side are returned as structured tool calls
- Tool outputs are fed back into the model for final response generation
Integrated Tool Capabilities
The adapter includes two pre-integrated tools to extend agent capabilities out of the box.
- Web Search Tool is powered by the Serper API and enables real-time information retrieval
- File Search Tool queries the OpenAI Vector Store to support RAG-based workflows
Streaming Support
The adapter replicates OpenAI's full streaming protocol, enabling incremental, real-time responses.
- Emits structured streaming events including response deltas, completion signals, and tool call signaling
- Supports incremental responses and final response validation
Key AWS Services Used
- AWS API Gateway serves as the secure entry point for all agent requests, handling JWT-based authentication and routing traffic to the /v1/responses compatibility endpoint
- AWS Lambda powers the Orchestration Backend, executing the FastAPI-based adapter logic and coordinating request handling, tool routing, and response formatting in a serverless, event-driven model
- Amazon Bedrock serves as the core LLM provider, supplying foundation models and guardrails for agent reasoning and query execution
- Amazon S3 provides persistent, scalable storage for agent conversation memory and session state, managed through the Strands memory manager
- Amazon CloudWatch delivers operational monitoring and observability across the platform, providing visibility into API activity, agent execution, and overall system health
Project Outcome and Impact
The Agents Adapter Layer enabled the organization to achieve multi-provider flexibility without disrupting its existing platform or engineering workflows.
Key outcomes include:
- Zero Disruption Migration. Existing agents required no code changes and achieved immediate compatibility with AWS Bedrock
- Multi-Provider Flexibility. The platform can now switch between OpenAI and Bedrock models, with the architecture designed to support additional providers going forward
- Faster Innovation. New tools and capabilities can be added at the adapter level with no impact on the agent layer, accelerating the pace of feature delivery
- Improved Scalability. The solution leverages AWS infrastructure for storage (S3), model execution (Bedrock), and API orchestration, enabling the platform to scale with enterprise demand
- Cost Optimization. The ability to dynamically select cost-efficient models helps reduce per-query costs as usage scales
- Extensibility. The plug-and-play adapter architecture supports the addition of new tools, APIs, and enterprise integrations without touching existing agent logic
Conclusion
By implementing a compatibility-first adapter architecture, the organization successfully decoupled its agent platform from a single LLM provider. It can now leverage AWS Bedrock alongside OpenAI without disrupting production workflows or requiring agent rewrites.
The platform demonstrates how thoughtful architectural abstraction can unlock multi-provider agility while preserving the engineering investments already made in agent logic and tooling.
Fission Labs specializes in designing and deploying production-grade AI and multi-agent platforms on AWS, enabling organizations to build flexible, scalable, and enterprise-ready AI systems with confidence.